CSV Variable Configuration¶

A CSV file consists of any number of records, separated by line breaks of some kind; each record consists of fields, separated by some other character or string, most commonly a literal comma or tab.
CSV Content Validation
OctoPerf validates your CSV file content. If you see validation errors, check Content Validation to understand and fix them.
CSV Variable Conflicts
OctoPerf detects conflicts when multiple CSV variables share the same file or column names. If you see conflict warnings, check Variable Conflicts to understand and fix them.
Note
A click on the blue variable name in the Usage section will copy it to the clipboard.
| Property name | Description |
|---|---|
| Name | Display name. The real variable names are in the column headers. |
| Usage | Usable variable names generated by this CSV variable. Click on one to copy it. |
| Description | The variable description text. |
| File | The CSV file, either select one from the existing files or upload a new one. Try to avoid using the same file for several variables, otherwise the behavior might be inconsistent. |
| Upload | Upload a new file, be careful this will override the column configuration. If you want to preserve it, upload a file with the same name inside the files menu. |
| Generate | Generate a fake dataset file using our build-in generator. |
| Encoding | The CSV file encoding, leave blank if UTF-8. |
| Delimiter | The character or string used to separate the fields in the uploaded CSV file. Usually a comma. |
| Quoted data allowed | A value may be enclosed in double-quotes if this option is selected. |
Example
Each time a Virtual User runs an iteration, it gets to use a line of the CSV file and populates one variable for each column.
For example if you run:
- A 60 minutes test scenario
- With 10 concurrent virtual users
- Each user takes 10 minutes to execute
Then you would need 6 lines per user (60/10 minutes), so a total of 60 lines in your CSV file to allow each Virtual user to have a unique set of values.
Quoted data allowed¶
If Allow quoted data is enabled, values in the CSV file may be enclosed in double-quotes. These will be ignored. E.g. you use a comma delimiter but one of your values contains a comma character. You can escape this value by placing it between quotes.
To include double-quotes within a quoted field, use two double-quotes. For example, with the CSV content (comma character used as a delimiter and quoted data allowed):
first,"second",last
1,2,3
1,"2,5","4""5"
Will convert to this:
| Column one | Column two | Column three |
|---|---|---|
| first | second | last |
| 1 | 2 | 3 |
| 1 | 2,5 | 4"5 |
Behavior¶
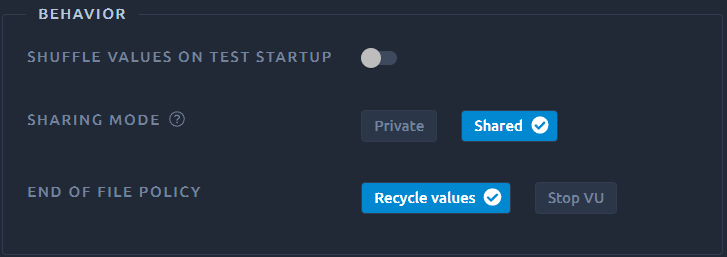
Activate "Shuffle values on test startup if you want the CSV lines order to be randomized before executing the test.
Other options are detailed below.
Sharing mode¶
Private¶
Selecting private means that each user will read the file sequentially on its own.
If you have 2 values in your file login1 and login2 and set it on Recycle, the result would be:
| Iteration | Virtual user 1 | Virtual user 2 |
|---|---|---|
| 1 | login1 | login1 |
| 2 | login2 | login2 |
| 3 | login1 | login1 |
Warning
If you use Shuffle values on test startup, we will only shuffle the file before the test. Which means that every user will still be using the same values in the same order. If that's not what you're looking for, you should try with Shared instead.
Shared¶
Shared means that the load generator will distribute a different value to each user when they ask for one.
Of course that remains true as long as there are unique values left in the file. See end of file policy for more details.
If you have 2 values in your file login1 and login2 and set it on Recycle, the result would be:
| Iteration | Virtual user 1 | Virtual user 2 |
|---|---|---|
| 1 | login1 | login2 |
| 2 | login1 | login2 |
| 3 | login2 | login1 |
Since unique values are only guaranteed at the load generator level, we also split the CSV between load generators so that each one gets a unique list of values.
End of file policy¶
Upon reaching the last line of the file you can set the CSV variable to behave in two ways:
- Recycle and loop back at the beginning of the file,
- Stop VU meaning the number of users running during your test might drop down. If this happens, a message will be visible in the JMeter logs.
Warning
If you use the same CSV file for several variables, the lines will still be used in a unique manner across all variables. This means that individual variables might appear to skip lines reserved by others variables. This leads to the file being consumed faster than expected, especially in combination with Stop VU ending condition.
Variables¶

In this section you see the first 8 values of the CSV file. You can use it to check if your configuration gives the expected output.
The offset represents the number of lines to skip at the beginning of the file. Lines skipped will be completely ignored by virtual users.
Each column header is editable. It lets you name each of the variables.
E.g. in the above screenshot, you could inject login using the ${login} syntax and password using ${password}.
Tip
You can leave empty column names. In this case the first row of the CSV file is used as variables names.
Generic CSV¶
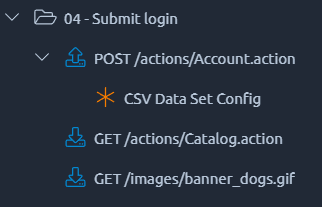
When importing from JMeter you can have two types of CSV variables:
- The regular one described in the first part of this page, when the CSV variable is declared at the root level of your JMX project,
- The custom CSV, when it is declared inside your threadgroup.
In that case the CSV value will go to next line on each iteration of this element, which can be useful for example inside a while.
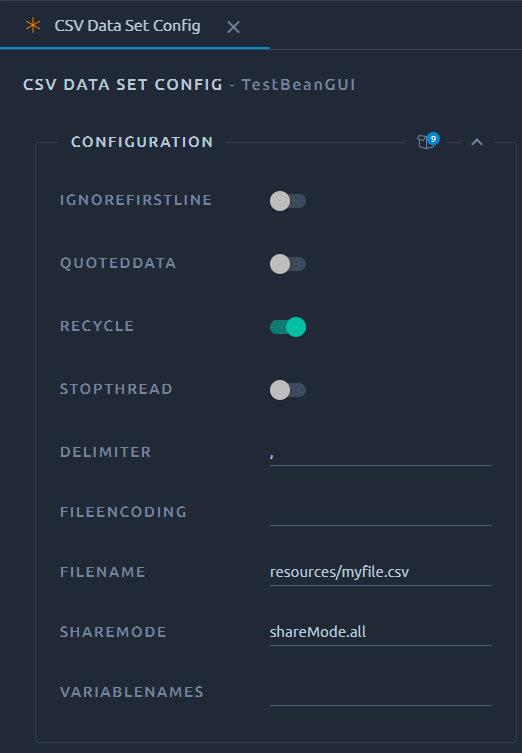
Since this is a JMeter action you will have to use the generic UI to do any adjustments. We will automatically convert the path to resources\filename.csv upon import, but make sure to still provide the file in the files menu or the test will fail upon launch.
Also this usage of CSV files is incompatible with our file splitting and usage of shareMode.all will just share the values locally on each load generator. This shouldn't be an issue because this particular usage is meant to iterate through the file on itself and as such doesn't require sharing with other threads. That's why we recommend using shareMode.thread in the shareMode field.
If you want to try it out, you can download and import the following JMX file: csv-data-set-config.jmx
CSVRead¶
CSV files in OctoPerf are parsed once every iteration.
If you need to skip a line or just want to parse the whole CSV in one iteration, you can use the __CSVRead function.
Warning
This function does not use the CSV variables at all, it works on an earlier version of CSV variables. Because of that you do not need to create a CSV variable to use it, just provide the file.

Example for a file named credential.csv:
${__CSVRead(resources/credentials.csv,0)}will be replaced with the first column of the current line,${__CSVRead(resources/credentials.csv,1)}will be replaced with the second column of the current line,${__CSVRead(resources/credentials.csv,next())}will skip to the next line.
Info
Value distribution is not configurable, it will always be equivalent to shared. Meaning that it can skip lines because another thread/user might already have taken the next one.
CSV file splitting¶
Uniqueness¶
The first thing to understand on CSV splitting is that we need to provide a unique set of values to each load generator. It is the only way we can guarantee that each user has access to a unique value because the underlying JMeter will distribute values at load generator level.
Another important notion is that each user running will pick a new value every time he runs a new iteration. You can work around this by using Flow control actions, but if you need each user to have a unique value, you want the last user to start before the first ones start their next iteration. Unless of course you have more values in your CSV than the number of users running.
Load generators¶
So the first step is to assess how many load generators will be required for a test. We do that based on several criterias, mostly the number of concurrent users. If you are using your own On-Premise Agents, check the provider configuration to understand how it works.
For instance when running a test with the following configuration:
Loginwith 500 concurrent users from Paris,Loginwith 2 000 concurrent users from California,Create accountwith 500 concurrent users from Sidney.
We will most likely end up using 4 load generators:

CSV Splitting¶
Now let's say we have a login.csv file and we want each user to pick a unique value during the test.
To do that we configure it to shared on the CSV configuration page.
Now you might think that we can split the file in 4, send a each load generator a share and proceed with the test. This is when we run into a second issue, because out of the 4 load generators, only 3 of them run the login virtual user.
Generally speaking, at this stage, we need to assess out of all the load generators how many of them will use a particular file. We do this by scanning the VU for each column name configured in the CSV and when we find one we give a share of this CSV to the load generators running it. This means that if a CSV is in use by several different VU profiles we can still guarantee unique values to each one of them. Or course if you don't want that, you can just duplicate your CSV variables instead.
In our earlier example we need to split the CSV file in 3 shares. We do a modulo on the file, in our case picking 1 line out of 3 for each subset:

Warning
Each subset is of equal size. Since we cannot accurately predict how many users will end on each load generator they all get the same amount of values. That can be misleading if you have very different number of users running. For example 10 users on one side and 1000 on the other will get both half of the file. You can compensate for this by providing more values.
CSV file matching¶
The only step remaining is to send each load generator its share of the file:

And in the background we edit each CSV variable to pick the new splitted file over the original CSV.