XPath1 Variable Extractor¶
XPath1 Variable Extractors lets you extract variables from HTML/XML responses using XPath1 queries.
Extracting variables from HTTP response helps you make your Virtual User have a dynamic behavior. Extracted variables can be injected in Logic Actions or HTTP Request Actions.
Warning
XPath1 should be avoided for HTML extractions, CSS Selector Extractor is the correct and performing solution. Also, since JMeter 5.0 (september 2018) you should use XPath2 Extractor as it provides better and easier namespace management, better performances and support for XPath 2.0.

| Field | Description |
|---|---|
| Name | Name of the variable created by this processor. Can be used with the ${...} syntax like any other variable. |
| From | This is for information purpose since this processor can only extract from Response body. |
| Include XML Tags | This option will return the entire XPath fragment instead of the text. Use it when you're not simply extracting a single attribute. |
| Query | The XPath Query to be used. |
| Default value | If no value is found, the variable will be equal to this. With match number All, you get the default value if you do not provide an index number. |
| Match number | Lets you choose how to deal with the processor having several results (or occurrences). Selecting All will change the behavior of your processor, see the dedicated section of the regex page for more details. |
Parser settings¶
Strict¶
It is possible to use two different parsers for your XPath expressions, the first one uses the Xalan XPath parser, it should be used on proper XML content only.

| Name | Description |
|---|---|
| Use namespace | If active, provide the namespace file and add this user property : xpath.namespace.config=namespaces.properties |
| Validate XML | Activates document validation. |
| Ignore whitespaces | Ignore Element Whitespace. |
| Download DTDs | If selected, external DTDs are fetched. |
Tolerant¶
The second one uses Tidy to convert HTML to XML beforehand. This option should be used when working on HTML content, or any non-XML format that requires proper conversion beforehand.

| Name | Description |
|---|---|
| Quiet | If enabled, limits the output to only document warnings and errors. |
| Report errors | If a Tidy error occurs, then set the Assertion accordingly. |
| Show warnings | This option specifies if Tidy should display warnings. |
Warning
Tidy will convert all elements and attribute names to lowercase. Tidy also attempts to correct improperly nested elements. Check its documentation for more info.
Debug¶
In order to validate the results of your extraction, you can use the debug panel.

The procedure is explained on the regex extractor page for both simple and multiple occurrences.
Example¶
From a browser¶
In this example we will be using the login page from our Petstore application. Make sure to import an HAR recording of this page.
The first step will be to navigate to this page and use the Right-click + Inspect menu of our browser to locate the element we want to extract:

Using the Copy XPath function we can get:
//*[@id="Catalog"]/form/div/input[1]
We can copy this directly in our XPATH1 extractor in OctoPerf, just adding on top of it that we want to extract the content of the value attribute with /@value:
//*[@id="Catalog"]/form/div/input[1]/@value
Simpler expression¶
Alternatively we could also rework our XPath Query to something simpler like:
//input[@name='_sourcePage']/@value
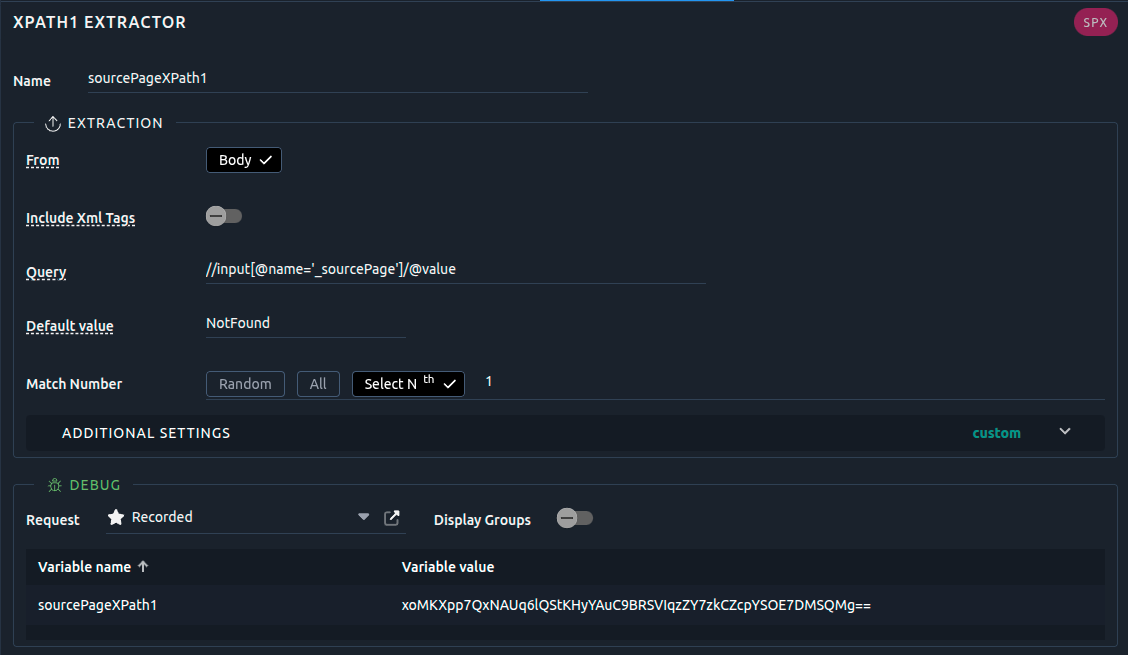
We would then pick only inputs named _sourcePage and this would be less dependent on the page structure. So provided the name is unique to this parameter we can get a more resilient expression if the application ever changes.
Tip
You can use third party tools like XPather to accelerate the design of your XPath expression. Just copy and paste the content of the response displayed on this page.